



Welcome, and thanks for tuning into this week’s AITU blog post 🙌. With again many new members, we continued our “Transformer” journey. After exploring how Transformers are used in the text-to-audio sphere, we were eager to learn how to extend the architecture to computer vision. The paper with the catchy title An Image Is Worth 16x16 Words - Transformers for Image Recognition at Scale published by Google Research in 2020, proposes the Vision Transformer (ViT) architecture, which extends the traditional Transformers to handle images as input for classification tasks. The paper is considered a milestone in computer vision, crushing various benchmarks in image classification. It marks a change of reign in the computer vision land dominated by convolutional architectures in previous years. This blog post summarises the paper’s background, main architectural ideas, results, and our thoughts. Enjoy! 🤗

📻 Vision Transformers
📍 Background. The paper Attention Is All You Need by Vaswani et. al from 2017 introduced the self-attention mechanism. It allowed modeling complex, long-term dependencies in sequential input data in a computationally light way. The architecture was originally proposed for machine translation. However, it was soon adapted for various NLP tasks, like text classification, PoS tagging, named-entity recognition (NER), and more - achieving state-of-the-art (SOTA) performance in most tasks. While Transformers achieved immediate success in the NLP domain, it took a bit more time to also see the first significant Transformers’ success in the computer vision field, which has been long dominated by convolutional architectures such as ResNet).
🔖 Previous Work. There have been, of course, several attempts to apply Transformers to computer vision tasks. But how does one translate an image to a sequence of tokens, the expected output of the Transformers architecture? Treating every pixel as a token does not work, as it does not scale to larger images. The computational complexity of self-attention grows quadratically with the number of input tokens, making pixel-level attention infeasible. Researchers, therefore, came up with compromises, e.g., applying self-attention in small neighborhoods of pixels or pre-processing images (reducing image resolution and color space) to apply pixel-level self-attention. None of these approaches yielded great results. Cordonnier et al. (2020) proposes an architecture conceptually very close to Google’s ViT (except using smaller patch sizes). Yet, they failed to prove the performance potential due to a lack of resources for large-scale training. While we acknowledge Google’s undisputable contribution, Cordonnier et al. l should probably receive more praise (at least more than 300 citations compare to Google’s 11k). So, also go check out their paper! 🤗
🏗️ The Architecture. The research team at Google set out to ”[…] apply the Transformer architecture to images with the fewest possible modifications”. A Transformer block expects a sequence of embedded tokens as an input sequence. Thus, the key question was how to extract a one-dimensional sequence of tokens from a two-dimensional image. ViT propose the following translation, which is also shown in the visualisation taken from the paper. 👇

First, the input image is split into fixed-sized patches. Therefore, you can imagine each patch as a three-dimensional matrix. However, Transformers expects the input tokens to be one-dimensional. Thus, the three-dimensional matrix is flattened into a one-dimensional vector. Yes, that’s right - despite all this information loss, ViT still managed to become SOTA in image classification. 🤯 The flattened vector is then projected via a Linear layer to a continuous-dense vector representation. In addition, each of these patch embeddings is concatenated with a learned positional embedding to give the model information about where the patch was initially extracted from. Finally, a special embedding token is added before all the patch embeddings. Its purpose will be explained in a second.
Since each patch should be able to attend over all the other patches, the patch embeddings are passed through multiple layers of Transformer Encoder blocks (if Decoder was used, then each patch would be able to attend only over the previous patches). Finally, to make the prediction, ViT uses only the special embedding token, fed through shallow multi-layer perceptron (a.k.a. simple neural network), which outputs the most likely class of the object in the input image.
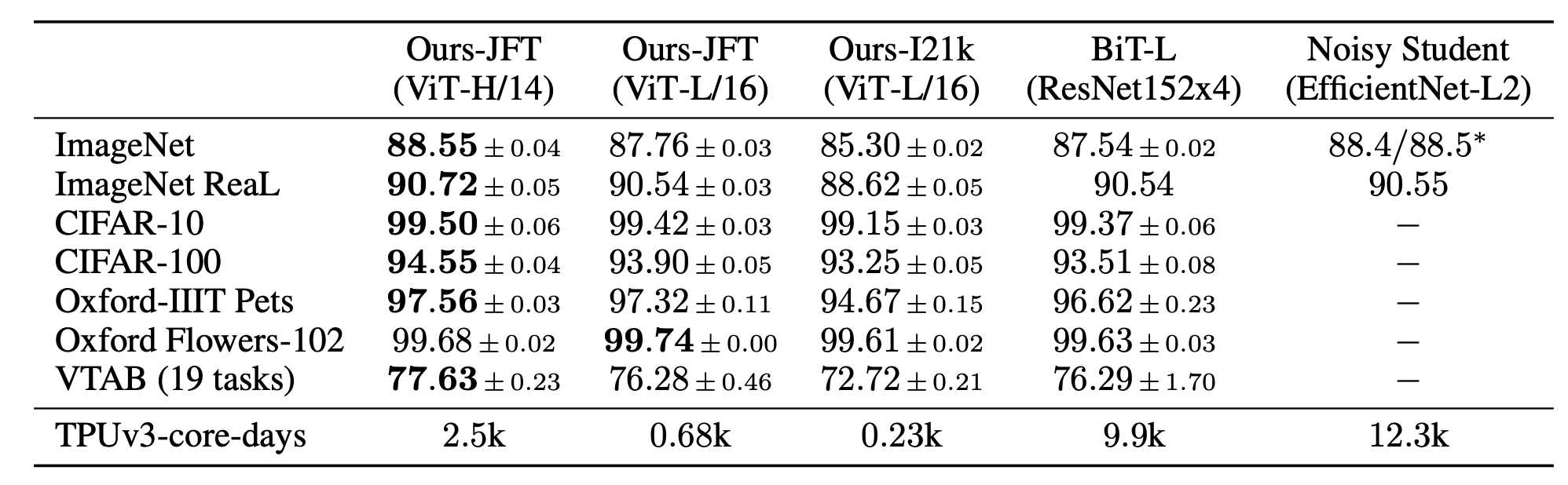
🎈 Results. The efficiency in training and inference of the Transformer architecture on modern hardware (GPUs/ TPUs) allowed Google to train their ViTs on enormous datasets (14M - 300M images). Although the model fails to model some of the features inherent to image data, ViTs set new SOTA performances on various benchmarks for image classification. The below table shows three versions of their ViT against two of the previous SOTA models, which are ResNet and Noisy Student. As can be seen, ViT performs best across all benchmarks with less training effort.
🔮 Our Key Takeaways
🌟 State-Of-The-Art. When trained at a large scale, Google’s ViT pushed the boundary in image recognition performance on numerous benchmarks. In doing so, it started a new era of Transformer-based models in the computer vision field. We encourage you to try them out. They are open-sourced and accessible, for instance, on Huggingface.
🤌 Keep it Simple. One thing about ViT we found especially remarkable: The researcher’s self-proclaimed goal was to “apply the standard Transformer architecture directly to images, with the fewest possible modifications.” This led to a model that, at its core, was not designed to handle image data (and its inherent features, like the strong local correlation of pixels). Our group was surprised how a model, inferior in capturing some of the intrinsic properties of its input data, still outperformed many of the most powerful convolutional neural networks specifically designed for image data. The takeaway from this is beautifully summarised by the research team: “Large-Scale Training Trumps Inductive Bias”.
🖼️ Handling Medium-Sized Images. One of the critical challenges when applying the Transformer architecture to images was deciding what constitutes a token. In the NLP domain, the definition is relatively straightforward. However, when dealing with image data treating each pixel as a single token does not scale as attention scores are computed pair-wise (quadratic running time) in each Transformer layer. One of the previous papers showed that a viable solution could be to split the image into 2x2 patches. This works for images with a small resolution. However, again scales poorly for images with higher resolution. Therefore, Google’s ViT uses patches of size 16x16 pixels enabling the model to handle even medium-resolution images.
🆘 Limited to Image Recognition. As of the paper’s release, ViT is limited to image classification. How the architecture can be extended to other common computer vision tasks, like object detection or image segmentation, is yet to be explored.
📣 Stay in touch
That’s it for this week. We hope you enjoyed reading this post. 😊 To stay updated about our activities, make sure you give us a follow on LinkedIn and Subscribe to our Newsletter. Any questions or ideas for talks, collaboration, etc.? Drop us a message at hello@aitu.group.