



Hey there! 👋 This week, we read the recently published paper The Contribution of Lyrics and Acoustics to Collaborative Understanding of Mood by Spotify Research. The paper tries to understand how different parts of a song, namely lyrics and acoustics, impact our perception of mood. 😟 😀 😨
The paper asks four separate research questions to break down the relationship, with two standing out the most:
Can training a lyrics-based model (…) produce accurate mood associations?
How much do lyrics contribute to moods compared to acoustics?”
The problem is not as simple as it might seem. Defining mood is highly subjective, and there are times when lyrics and acoustics don’t match. It has been found that lyrics are crucial to sad songs, but moods like “chill” and “relax” are almost exclusively dictated by acoustics. And that’s not all… both of those things can happen at the same time!

“Somebody that I used to know” is the best example of this duality. While the lyrics are sad and heartbreaking, the song is often included in chill and relaxed playlists due to its pleasant acoustics. 🎸
The researchers at Spotify tackle this issue by allowing multiple moods to describe a song (in fact, it allows each song to have 287 moods). It also uses a huge dataset of Spotify users’ playlists and, of course, Transformers. After all, how can we have innovation without transformers nowadays, right? 😅 Let’s see what the Swedes came up with 👇
📻 The Impact of Lyrics and Acoustics on Mood
📌 Background. The task of mood prediction is not new. It was already introduced in 2007, but it was limited to acoustics at that time. Then, in 2010, the first models using a simple bag-of-words (BoW) approach emerged, significantly outperforming previous work. In 2018, Delbouys et al. made use of audio features together with lyrics, but, most importantly, they also used the most advanced approaches to process text known at that time - GRUs, LSTMs and Convolutional Networks. This makes the paper by Spotify Research the first one to use transformer-based architecture for the task of mood prediction at scale.
📝 Data Collection. Before a model can be trained, it needs data. The researchers were aiming for a dataset of significant song-mood pairs, and so they defined 287 potential mood descriptors (like chill, sad, happy, etc.) that they wanted to match against as many songs as possible to make the analysis robust.
That’s a good time to start wondering, how do you label hundreds of thousands of songs using almost 300 classes?

As you can imagine, creating such a dataset manually is a huge annotation task, as it requires annotating each song to almost 300 mood descriptors. Luckily, it’s Spotify, the world’s biggest music streaming platform, doing this research project. Their user data unlock methods of data collection that are not feasible for anybody else. To build their dataset of song-mood pairs, they used the wisdom of the crowd approach by scraping their entire user database of 4 billion playlists.
They used the title and description that users give their playlists to associate all songs in the playlist with these moods. Yes, that’s right, your Calm playlist was used in this research project. And yes, that’s right, if you had a heavy metal song in there, it would have landed in their dataset with a label calm.
This is not where the story ends, as the initial scrape was full of noisy song-mood associations. To ensure that co-occurrences of songs and moods are statistically significant, the researchers calculated Pointwise Mutual Information (PMI), which is a measure of association. The intuition behind the metric is that it quantifies how much more (or less) a song and a mood co-occur than we would expect if they were completely independent. At this point, every song and mood pair got a PMI score, which can be interpreted as a metric of association correlation.
When plotting the empirical distribution of these scores (in fact a normalised version, but we are not going to get into that) of every song-mood pair, it became quite clear that most songs and moods are not associated strongly negatively or positively. The authors filtered all song-mood pairs with a threshold of ±0.1, which means that only songs with a PMI score below -0.1 or above 0.1 were considered for further analysis. After filtering, they ended up with around 2 million (song, mood) pairs for training.

🔮 Zero-shot Learning. The first research question of the paper was “What can lyrics tell us about moods with no training in lyrics-mood associations?” It is quite weird. Isn’t the point of machine learning models being trained, after all? How can a model with no training predict anything? It’s just a pre-defined function in that case, isn’t it?
The answer is, it depends. There exist models that can predict valuable output without task-specific training, called zero-shot learning models. By definition, they allow predicting a class without seeing a single labeled example during training. For a deeper dive into how they work, take a look at this blog post.
For our needs, we can limit ourselves to two tasks in natural language processing that can be used without further training for the mood prediction task: NLI (Natural Language Inference) and NSP (Next Sentence Prediction). The first one takes two sentences and checks if they are in accordance (entailment) or if they contradict one another. The latter checks if one sentence can follow the other, so if they are coherent.
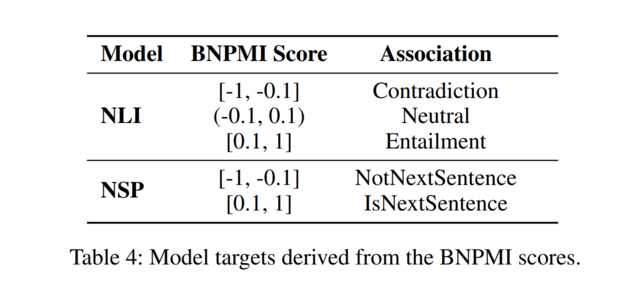
The first sentence in the mood prediction setting is the entire lyrics. The second one is a bit trickier - it’s our mood descriptor, but changed into a sentence depending on what part of speech it represents. Then the output is mapped to either the mood being there (Entailment, IsNextSentence) or not being there (Contradiction, NotNextSentence). In NLI, the authors discard the probability of neutral prediction.
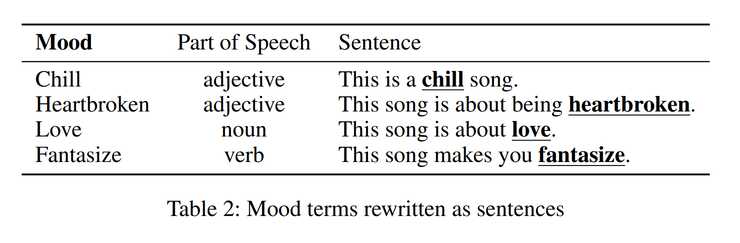
🎤 Lyrics Models. Next comes the main part, trying to answer the question “Can training a lyrics-based model (…) produce accurate mood associations?”
The lyrics models are the same in structure as the zero-shot learning models, but they’ve been through what we all like most, fine-tuning. Both NLI and NSP tasks are trained on transformer-based models. So, Spotify researchers simply took the BERT models and fine-tuned them for the task of mood prediction, which resulted in a huge jump in performance - but more about that in a second. BERT can really do some heavy lifting, huh? 👀 (image from here).

They also trained a baseline model, which converted the lyrics into Bag-of-Words (BoW) and used Logistic Regression for binary classification. So, in total, they trained 287 binary classification models, one for each mood descriptor.
🎹 Acoustics Model. For the acoustics model, the authors used the Spotify API to extract continuous features representing the instrumental layer of songs and used a Logistic Regression model for each mood to predict whether it is there or not. This approach is very similar to the lyrics BoW baseline. This poses a serious limitation. The performance of transformer-based approaches to process lyrics is not directly comparable with scores obtained for acoustics that used a much simpler model. The only comparable score is the one obtained by the model based on BoW.

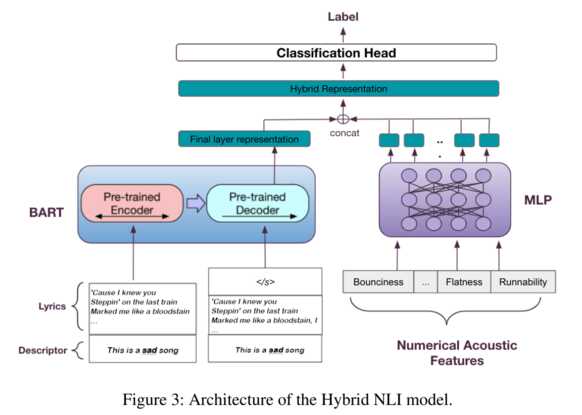
🎼 Hybrid Model Architecture. Finally, the two models were combined into one - called a hybrid model. The left part of the final architecture is quite similar to the general BERT model for the NLI task (used as the final model for lyrics, beating NSP’s performance). The only difference is that it stops before the classification layer to wait for the hidden representation that comes from the additional part of the structure - the acoustics part.
The acoustics hidden representation is generated by a Multi-Layer Perceptron that takes numerical acoustic features as input. The two representations are concatenated, and then they are run through the classification head. Finally, the usual label for the NLI task is returned - entailment or contradiction.
🏆 Results
The results for all the above approaches are summarized in the table below. The zero-shot learning models have significantly lower performance than the remaining approaches, although still quite remarkable, especially the NSP model. The F1 score of 85.38 is not that far from the first fully-trained approach; the baseline BoW model scored 91.74.
The fine-tuned transformer-based models achieved a significantly better performance than the baseline, oscillating around an F1 score of 96-97. Interestingly, this time the NLI took the lead as opposed to the zero-shot models.
The sole model for acoustics ended up having a worse performance than the lyrics baseline, demonstrating that lyrics play a bigger role than acoustics in establishing song’s mood. It’s quite a lucky coincidence - if the acoustics model had performed better than the BoW approach but worse than the transformed-based one (guaranteed!), it would have been impossible to interpret the results!
Last but not least, the NLI hybrid model performed better than any other model, hinting that acoustics and lyrics complement each other in establishing the song’s spirit. However, the performance is only slightly better.

🔍 Key Takeaways
🎧 Lyrics are more important. The paper demonstrated that lyrics play a bigger role than acoustics in establishing the mood of a song. However, hybrid models achieved even higher performance than the lyrics-only models, showing that lyrics and acoustics often complement each other.
🙋 Learning subjective patterns. We can learn patterns that correlate songs to moods, even though they are subjective. By having access to large amounts of data without the need to annotate it, the lack of inter-human agreement can be overcome by pure scale.
🔧 Transformers are everywhere. Another day, another task where we see transformers shine. The more we explore different machine learning areas, the more we see how universal they are.
🌟 Zero-shot learning. There exist models that can predict a label without seeing it before. Will there be a general AI in the future, performing any task we throw at it?
📣 Stay in touch
That’s it for this week. We hope you enjoyed reading this post. 😊 To stay updated about our activities, make sure you give us a follow on LinkedIn and Subscribe to our Newsletter. Any questions or ideas for talks, collaboration, etc.? Drop us a message at hello@aitu.group.