



Welcome to AITU’s weekly blog post! 🙌 Last week, we took a closer look at the new family of large language models (LLMs) proposed by Meta - LLaMA 🦙. LLaMA stands for Large Language Model Meta AI, a ‘creative’ acronym 😅. Shortly after its release, Twitter was flooded with posts by deep learning enthusiasts from all around the world. Of course, the ‘father’ of deep learning and Meta’s Chief AI Officer, Yann Le Cun also commented on one of Meta’s biggest releases in a while in this Twitter post.
LLaMA is Meta’s effort to democratise access to large language models by training and releasing the novel model in an ‘open’ source manner. Meta claims that LLaMA-65B, the largest model from the family, vastly outperforms GPT3 which has 150B parameters.
Of course, we had to read the paper to see what is behind the hype. So, without further ado, let’s jump right into it 🚀
LLaMA: Open and Efficient Foundation Language Models
📍 Context. In recent years the paradigm “more parameters = better performance” has dominated the deep learning field and has led to ever larger models. And we mean, ridiculously large. For example, Google’s 500B PaLM or the 150B GPT-3 by OpenAI. However, a recent paper by Hoffmann et al. (2022) suggests a more nuanced relationship between model size and performance: They found that under a fixed training budget, smaller models outperform larger models. Their discovery is important: It means that the truly large models are only superior when trained on huge amounts of data with huge computing resources. Who can perform such training? Of course, only the big tech companies. For the rest of us, smaller models are the way to go and Hoffman’s “scaling laws” gives us intuitions of ideal model sizes with limited resources. In the attempt of democratising the power of LLMs, Meta AI took inspiration from this paper and designed the LLaMA LLM family with fewer parameters and more data. Moreover, they coined the term inference budget, which they deem more important than the training budget for real-world applications. In the paper they explain:
In this context, given a target level of performance, the preferred model is not the fastest to train but the fastest at inference, and although it may be cheaper to train a large model to reach a certain level of performance, a smaller one trained longer will ultimately be cheaper at inference.
What does this mean? Well, the released LLMs are chosen in a way, such that they are as quick as possible during inference. This is great news for all developers out there, who build applications on top of foundation language models 🚀
📚 Pre-training data. LLaMA was trained solely on publicly available datasets, including Wikipedia, Books, and Stack Exchange. The complete overview can be seen in the figure below.
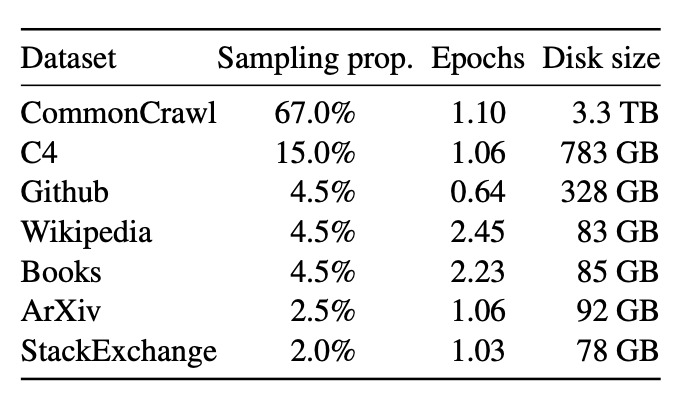
Each dataset was carefully preprocessed to ensure high-quality input data. For instance, only highly ranked answers from Stack Exchange were chosen. Additionally, high-quality sources, such as books, were shown more often (see the number of epochs) than lower-quality ones. Finally, it is important to pause for a moment and appreciate the fact that we have been able to gather such a vast amount of data over the past 20 years. Without this data, LLMs would not be possible. 👏
🏗️ Model architecture. Since the original release of Transformers by Vaswani et al., there have been new ideas for improving the architecture. In the LLaMA paper, they adopt some of these:
- Pre-normalization. (GPT3) To improve training stability, they normalise the input to each sublayer instead of normalising the output.
- SwiGLU activation function (PaLM). This is a new activation function that replaces ReLU.
- Rotary Embeddings [GPT Neo]. They add rotary positional embeddings at each layer of the network instead of absolute positional embeddings.
Although these are important improvements, AI researcher Yannic Kilcher attributes the success of the LLaMA model to the exceptional engineering effort that enabled the model’s efficient implementation and training procedure, as discussed below. 👇
🆙 Optimisations. While the optimisations are important, it is beyond the scope of this post to go into much technical depth. We summarise the two techniques used at a high level:
- An efficient implementation of the causal multi-head attention operator that does not store the attention weights or compute the key/query scores that are masked due to the causal nature of the language modelling task (next token prediction). To put it simply: They removed calculations that are not needed.
- A reduction in the number of activations that are recomputed during the backward pass using checkpointing via a custom implementation of the backward function for transformer layers instead of relying on PyTorch’s Autograd. A great 1-minute explanation can be found here.
💪 Training: Model sizes range from 6.7B to 65.2B, using standard 32-bit float. Therefore, loading the model into memory requires 26.8GB to 260GB! However, with quantisation (reducing all weights and activations in the model to a smaller data type), it is possible to run the smallest model on a Raspberry Pi. 🤯 The figure below provides an overview of all the models.
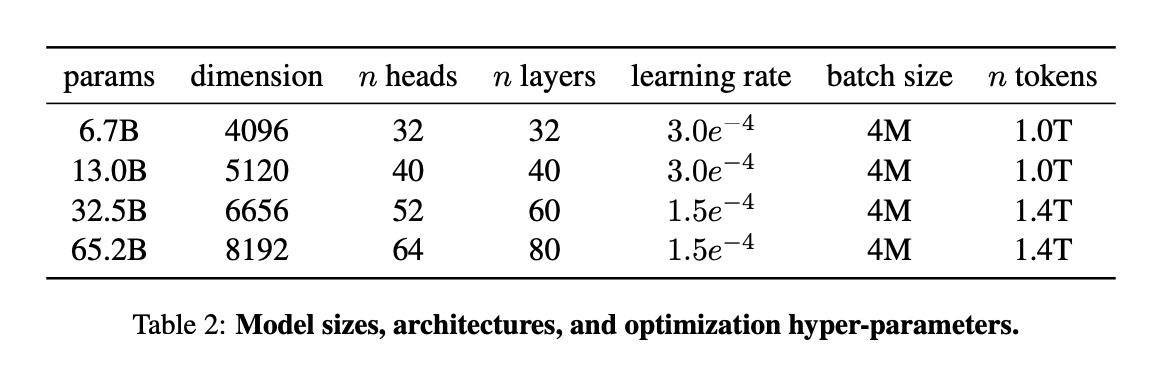
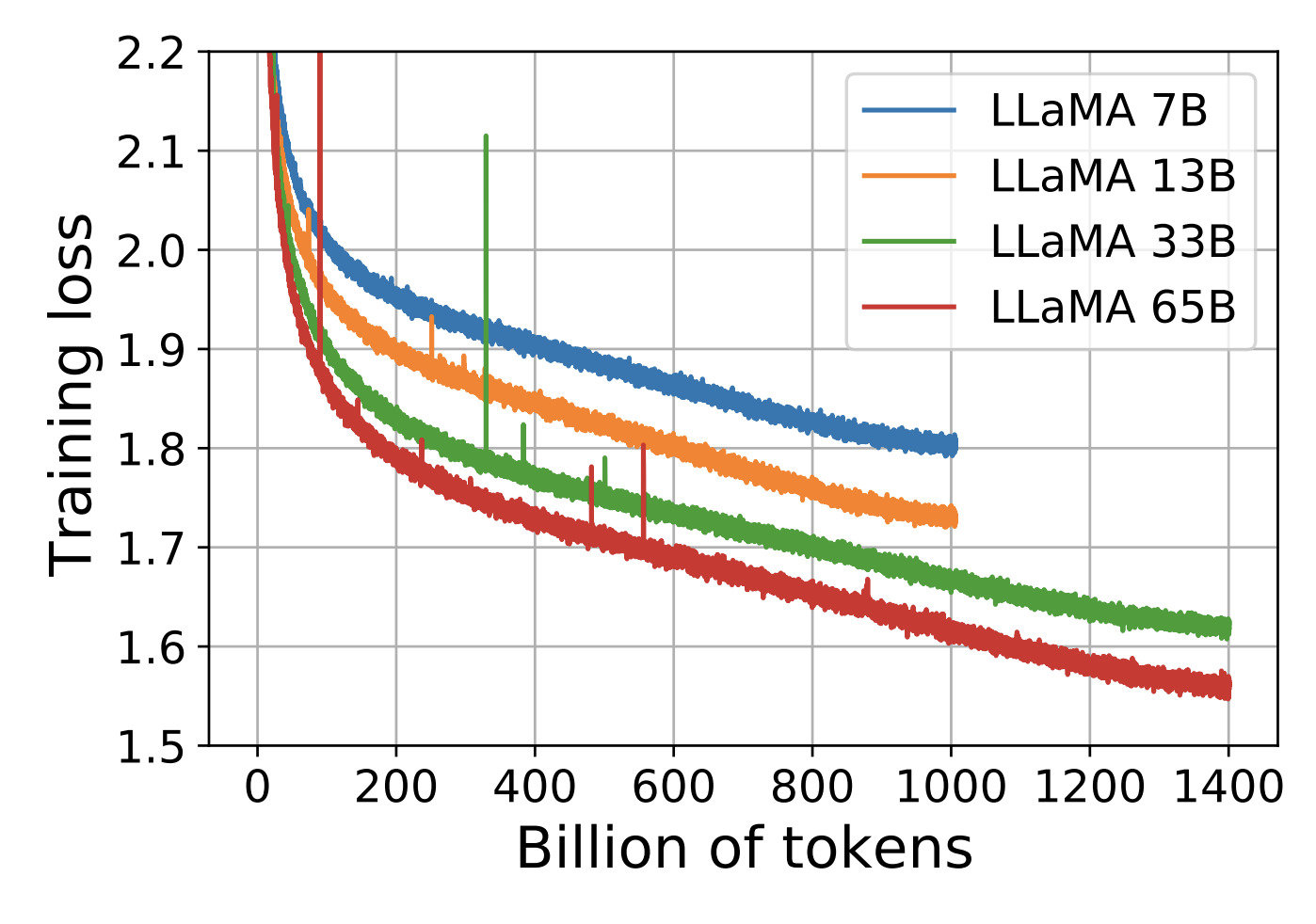
The models were trained on 2048 A100 GPUs with 80GB of RAM, and a processing capacity of 380 tokens/sec/GPU. Despite this, training the largest model for 1.4T tokens still took 21 days. The authors of the paper argue that releasing the model to the public balances out the CO2 emissions produced. 😅 Finally, the figure below shows the training curves. While inspecting the training curves, we noticed that all loss curves were still visibly decreasing, indicating that the models were still learning. This suggests that there is even more room for improvement. 💫
📊 Results. The models underwent testing on various benchmark datasets with tasks that ranged from common reasoning to code generation and mathematical reasoning. For example, when tested on natural language questions, LLaMA models performed as well as, if not better than, much larger models such as PaLM, and even outperformed larger models like GPT-3. The models were also tested for toxicity and bias. Interestingly, when asked to generate toxic responses more respectfully, the toxicity score improved for all models except for the largest one, whose score increased. 🤷♂️ Overall, the results demonstrated that the LLaMA family of models, despite being smaller, is incredibly powerful in a wide range of applications. 💯
🔮 Key Takeaways
⚖️ Non-Profit Open-Source vs. Full-Profit and Secretive. Meta is one of the major contributors to open-source. Frameworks we all love, such as PyTorch or ReactJS originate from Meta. While there has been criticism of Meta’s decision to release the LLaMA models “only” under a non-commercial license, the set of released models marks a huge step forward on the journey of truly accessible LLMs. We were especially happy to see this in the light of a more and more competitive landscape, where companies start to keep their models secret in an attempt to gain a competitive advantage (*Cough, cough* - GPT-4).
💪 Foundation Models. The trend of foundation models keeps going and is promising for the wider adoption of LLMs. A foundation model, like LLaMA, is a large model trained on vast quantities of unlabelled data at scale. The pre-trained base can then be used in a zero- or few-short setting or fine-tuned with significantly less compute resources to achieve state-of-the-art results. Thanks to the great work of the community around Hugging Face, such foundation models are nowadays available via simple APIs to anyone. Most of them can even run on an average laptop. As a result, individuals and businesses of all sizes can take advantage of the recent advances in AI.
🔬👨💻 Engineering > Science. This is a common theme that we have picked up in multiple of the papers that we have read: Recent advancements in the AI field seem to be the result of great engineering effort rather than scientific discovery. The LLaMA paper is a great example of this.
📣 Stay in touch
That’s it for this week. We hope you enjoyed reading this post. 😊 To stay updated about our activities, make sure you give us a follow on LinkedIn. Any questions or ideas for talks, collaboration, etc.? Drop us a message at hello@aitu.group.